Article posted on:Aug 25, 2023
Article updated on:Aug 25, 2023

Оригінальна стаття: https://faculty.cc.gatech.edu/~parikh/nameable.html
[ Іспанською ]
Анотація
Візуальні атрибути, які можна назвати людиною, пропонують багато переваг, якщо їх використовувати як ознаки середнього рівня для розпізнавання об’єктів, але існуючі методи збору відповідних атрибутів можуть бути неефективними (коштують значних зусиль або досвіду) та/або недостатніми (описові властивості не обов’язково мають бути дискримінаційними). Ми представляємо підхід до визначення словника атрибутів, який є зрозумілим людині та розрізняє. Система приймає зображення з мітками об’єкта/сцени як вхідні дані та повертає як вихідні дані набір атрибутів, отриманих від людей-анотаторів, які розрізняють цікаві категорії. Щоб забезпечити компактний словниковий запас і ефективне використання зусиль анотаторів, ми 1) показуємо, як активно збільшувати словниковий запас, щоб нові атрибути вирішували плутанину між класами, і 2) запропонувати нову багатоманітність «іменуваності», яка розставляє пріоритети атрибутів-кандидатів за ймовірністю їх асоціації з іменуваною властивістю. Ми демонструємо підхід із кількома наборами даних і показуємо його явні переваги перед базовими лініями, у яких відсутня модель іменування або покладається на список атрибутів, наданих експертами.
Мотивація
Щоб бути максимально корисними, атрибути повинні бути
Дискримінаційні : щоб їх можна було надійно вивчити в доступному просторі функцій і ефективно класифікувати категорії
і
Можливість іменування: щоб їх можна було використовувати для нульового навчання, опису раніше невидимих випадків або незвичайних аспектів зображень тощо.
|
Існуючі підходи |
Дискримінаційний |
Іменний |
|
Список, створений вручну |
Не обов'язково |
Так |
|
Майнінг мережі |
Не обов'язково |
Так |
|
Автоматичний розподіл категорій |
Так |
Немає |
|
Запропоновано |
Так |
Так |
Пропозиція
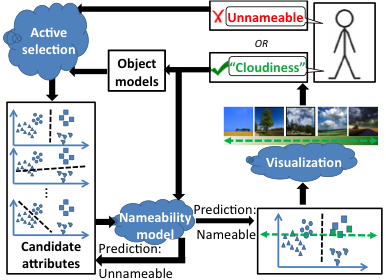
Ми пропонуємо інтерактивний підхід, який спонукає людину в циклі надавати імена для гіпотез атрибутів, які він виявляє. Система приймає як вхідні дані набір навчальних зображень із пов’язаними мітками категорій, а також один або більше просторів візуальних функцій (сутність, колір тощо), і повертає як вихідні дані набір моделей атрибутів, які разом можуть розрізняти категорії інтерес.
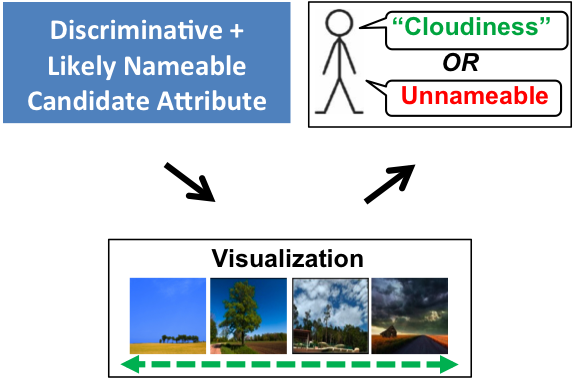
Щоб візуалізувати атрибут-кандидат, для якого система шукає ім’я, людині показують зображення, відібрані вздовж нормального напрямку до деякої розділової гіперплощини в просторі ознак. Оскільки багато гіпотез не відповідатимуть тому, що люди можуть візуально ідентифікувати та коротко описати, наївний процес виявлення атрибутів — процес, який просто циклічно перебирає дискримінаційні розділення та просить анотатора назвати або відхилити їх — є непрактичним.
Замість цього ми розробляємо підхід, щоб активно мінімізувати кількість безглуздих запитів, які надсилаються анотатору, так що людські зусилля здебільшого витрачаються на призначення значення розділам у просторі ознак, які насправді його мають, на відміну від відкидання неінтерпретованих розділень.
Ми досягаємо цього за допомогою двох ключових ідей: на кожній ітерації наш підхід:
1) фокусується на гіпотезах атрибутів, які доповнюють класифікаційну силу існуючих атрибутів, зібраних до цього часу, і
2) прогнозує можливість іменування кожної дискримінаційної гіпотези та визначає пріоритетність тих, які, ймовірно, можна назвати. Для цього ми досліджуємо, чи існує якась багатоманітна структура в просторі іменованих роздільників гіперплощин.
Підхід
У запропонованому нами інтерактивному підході необхідно вирішити три основні проблеми:
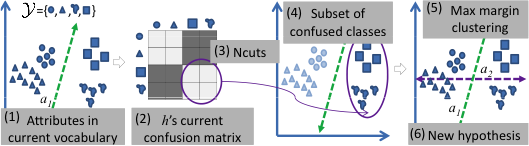
Виявлення гіпотез атрибутів: ми активно виявляємо гіперплощини у просторі візуальних функцій, які відокремлюють підмножину класів, які зараз найбільш заплутані. Ми використовуємо ітеративну кластеризацію з максимальною маржею, щоб виявити таке поділ.
Прогнозування іменності гіпотези : на кожній ітерації ми будуємо багатоманітність іменування, використовуючи суміш імовірнісного аналізу головних компонент, щоб відповідати відповідям користувача, зібраним на даний момент . Багатовид вивчається в просторі параметрів гіперплощини. Як показано нижче, багатоманітність може ефективно передбачати можливість іменування нової дискримінаційної гіперплощини.
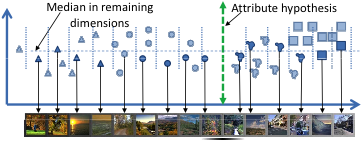
Візуалізація атрибута: Щоб представити користувачеві візуалізацію гіперплощини, ми вибираємо зображення з набору даних таким чином, щоб їх відстань, перпендикулярна гіперплощині, змінювалася, але будь-які варіації вздовж гіперплощини були мінімізовані. Потім користувача просять назвати візуальну властивість, яка змінюється на зображеннях зліва направо. Ця назва разом із параметрами гіперплощини формує наш нещодавно відкритий атрибут.
Оцінка
Ми оцінюємо наш підхід на двох наборах даних по 8 категорій кожен: розпізнавання сцен на відкритому повітрі (OSR) і підмножина набору даних Animals with Attributes (AWA). Для обох наборів даних ми використовуємо суть і колір.
Щоб автоматично оцінити наш запропонований підхід, ми збираємо анотації іменування всіх дискримінаційних гіперплощин (247) в обох просторах ознак обох наборів даних. Ми показуємо візуалізацію кожної з гіперплощин 20 суб’єктам Amazon Mechanical Turk і просимо їх вказати, наскільки очевидні зміни видно на зображеннях (за шкалою від 1 до 4), і яка властивість зміни. Приклади відповідей наведено нижче:
"Чорний"
"Плямистий"
Безіменний
"зелений"
"перевантажений"
Ми вважаємо гіперплощину такою, що можна назвати, якщо отриманий середній бал «очевидності» перевищує 3. Цей пул анотованих гіперплощин тепер можна використовувати для проведення автоматичних експериментів, імітуючи при цьому реального користувача в циклі.
Результати
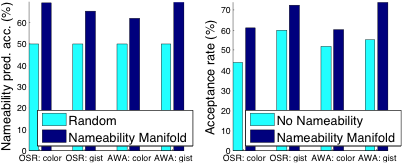
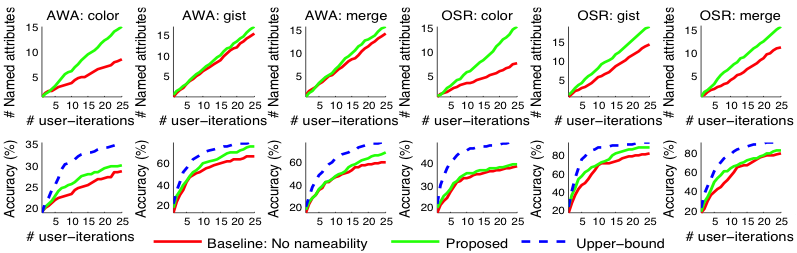
Лише дискримінаційна базова лінія: порівняно з базовою лінією, яка представляє дискримінаційні гіперплощини користувачеві без моделювання іменності (див. нижче), ми виявили, що наш підхід виявляє більше іменованих атрибутів з тими самими зусиллями користувача, що також сприяє кращій продуктивності розпізнавання.
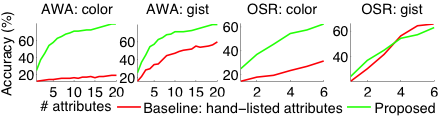
Лише описовий базовий рівень: з іншого боку, порівняно з суто описовими атрибутами, наш підхід знаходить більше дискримінаційних атрибутів, що також призводить до покращення продуктивності розпізнавання (див. нижче).
Автоматично створені описи: Виявлені нами атрибути можна використовувати для опису раніше бачених і раніше невидимих (наприклад, zerba) зображень, як показано нижче.
Публікації
Інтерактивне створення розрізнювального словника іменованих атрибутів
Конференція IEEE з комп’ютерного зору та розпізнавання образів (CVPR), 2011
[ додатковий матеріал ] [ плакат ] [ слайди ]
Інтерактивне виявлення іменованих атрибутів, специфічних для завдання (Анотація)
Перший семінар з детальної візуальної категоризації (FGVC)
проводиться спільно з IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 20 11 (Нагорода за найкращий постер)
[ плакат ]